MENUMENU
- Services
- Borrow, Renew, RequestHow to borrow materials, request pdf scans, and interlibrary loans.
- Study SpacesAreas for individual and group study and how to reserve them.
- Course ReservesHow to access course-related materials reserved by faculty for their students.
- Services for Faculty and InstructorsA list of services offered to faculty and instructors at the University of Hawaii at Manoa.
- Library InstructionRequest library instruction for your course or register for a workshop.
- Suggest a PurchaseSuggest new materials that support teaching, study, or research.
- Other ServicesApply for a research carrel or reserve our lactation room.
- Loanable TechnologyCables, adaptors, audio and video equipment, and other devices
- Research
- CollectionsAn overview of the various library collections.
- Online DatabasesSearch across 100s of library databases.
- JournalsSearch journals by title or subject.
- Research GuidesGuides for subjects, select courses, and general information.
- OneSearchFinds books and other materials in the UH Manoa Library's collection.
- Scholarly CommunicationLearn about scholarly communication, open access, and our institutional repositories ScholarSpace, eVols, and the UH System Repository.
- Help
- Ask a LibrarianGet help by email, online form, or phone.
- FAQFrequently asked questions.
- Accessibility and DisabilityInformation about accessibility and disability.
- Subject LibrariansFind a librarian for a specific subject.
- Copyright HelpLinks to resources about copyright.
- Technology in the LibraryWireless access, scanning, printing.
- English 100 StudentsThe starting point for English 100 research.
- Request a Research AppointmentContact us to schedule an in-person appointment.
- About
- Office and Department ContactsView a list of the departments at the library.
- Jobs at the LibraryFaculty, staff, and student job opportunities.
- Staff DirectoryContact information for staff at the library.
- ExhibitsCurrent and past exhibits at the library.
- Support the LibraryFind out how you can support the library.
- Our LibraryAnnual reports, mission, values, history, and policies.
- VisitingHours, directions, floor plans
- News, Blogs & EventsNews, blogs & events from the library.
- ILL
- My Account
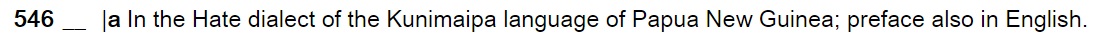
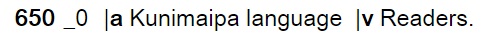
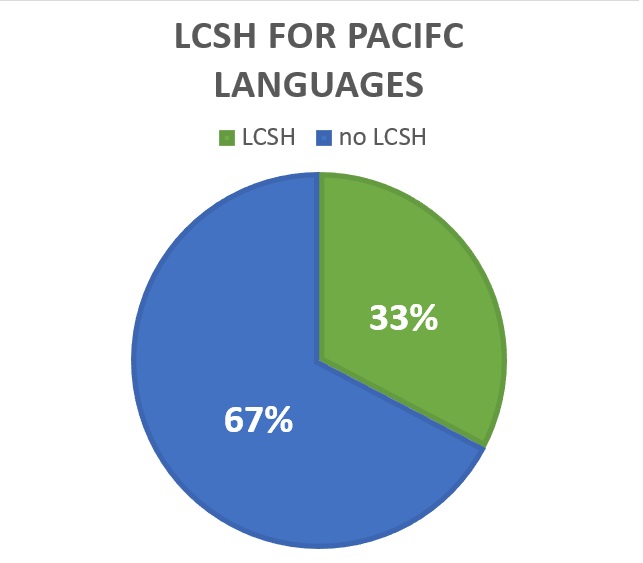
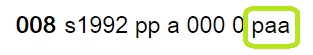

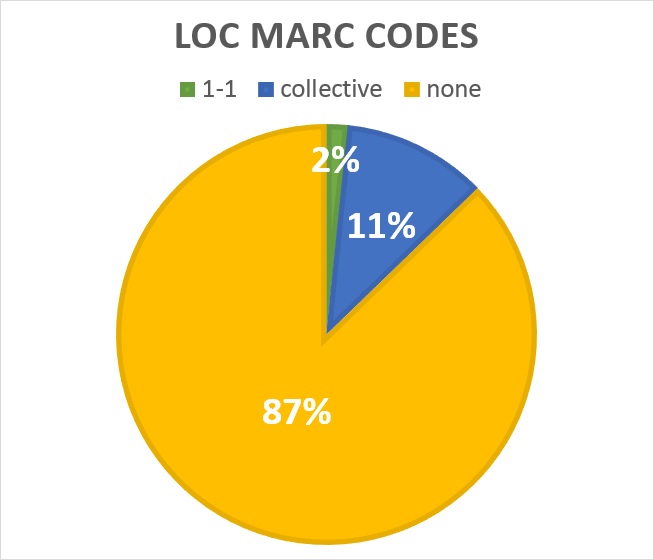 The Library of Congress (LoC) maintains a
The Library of Congress (LoC) maintains a